Simple Map Dashboards with Observable Framework
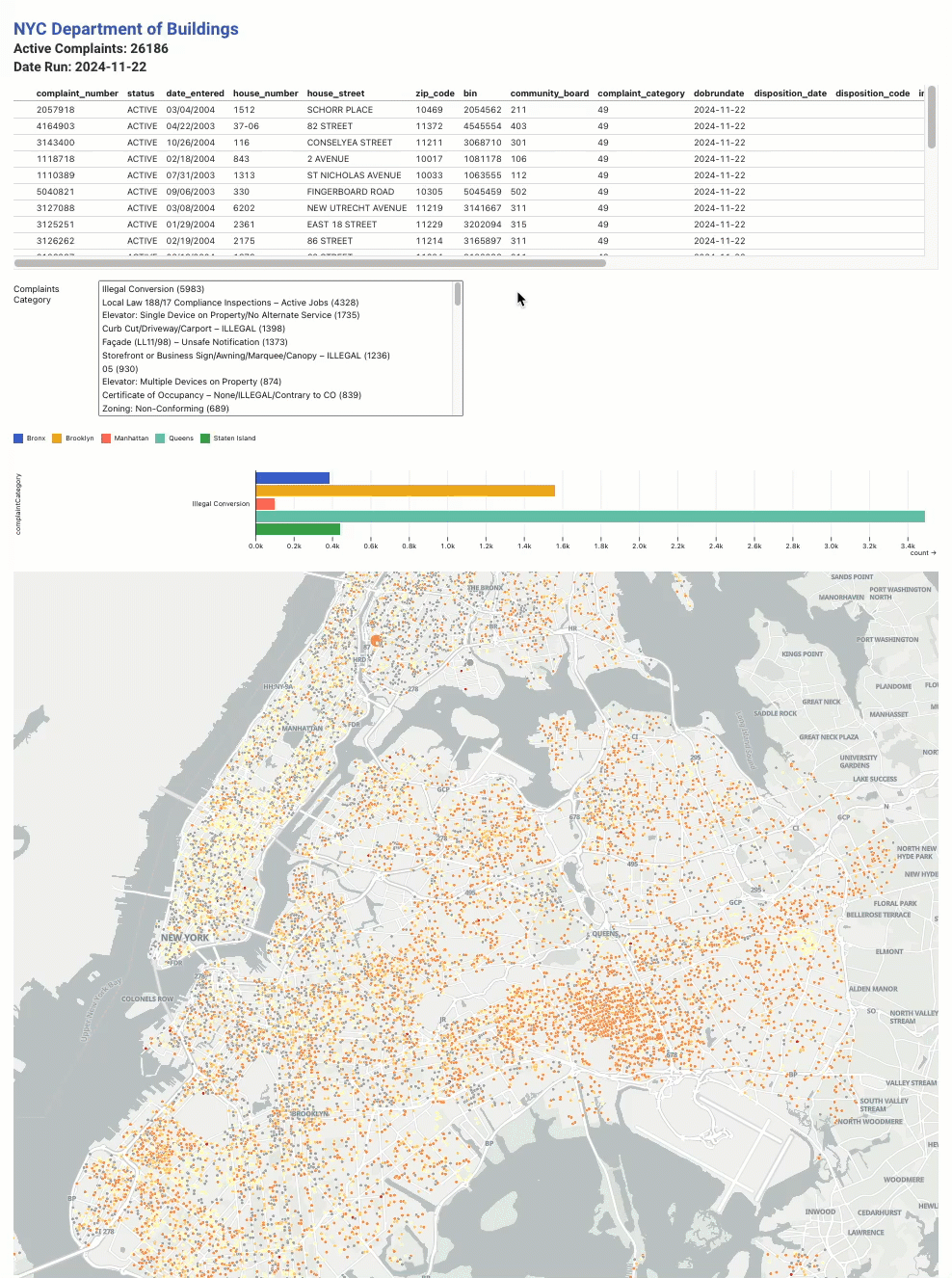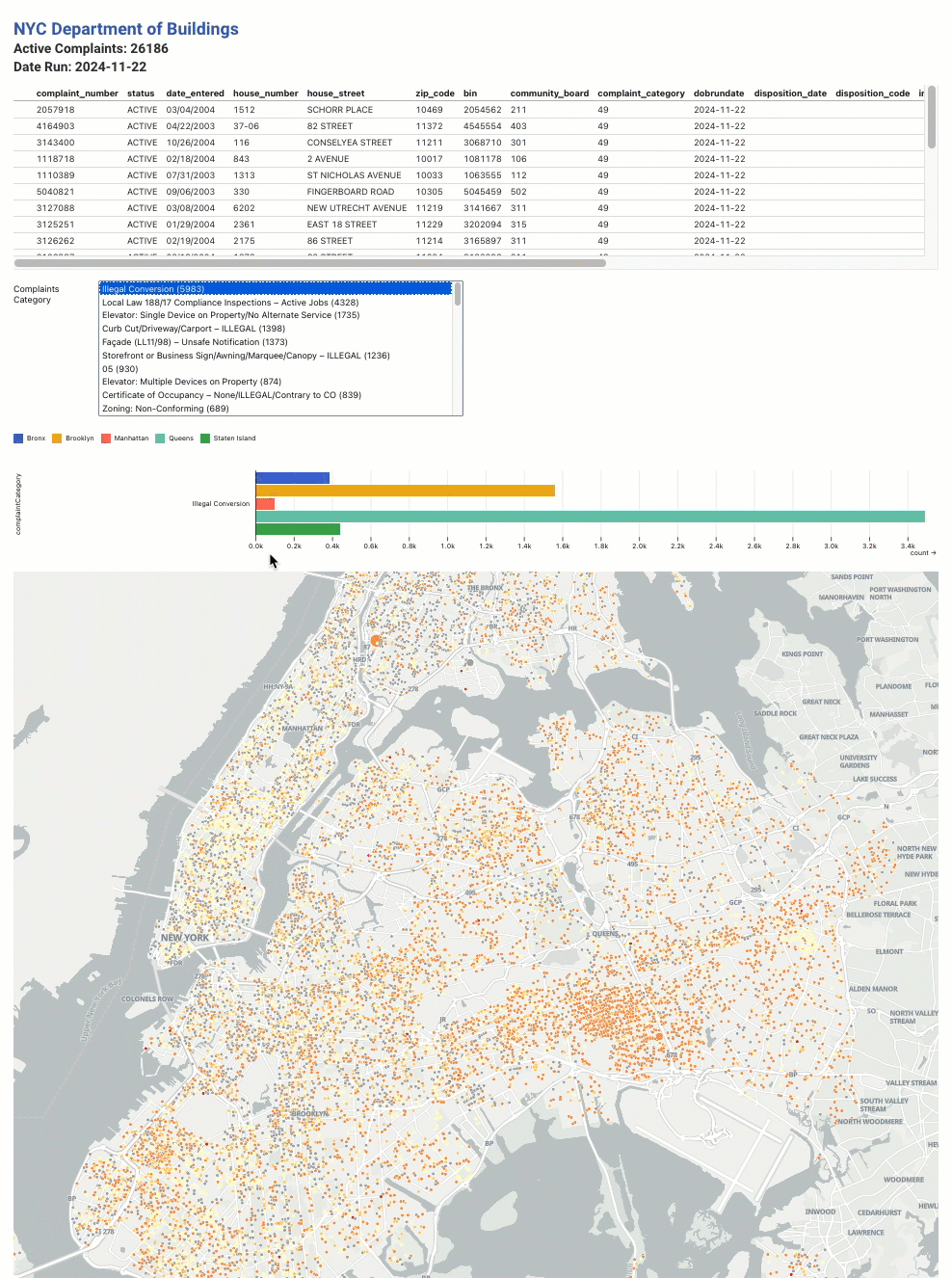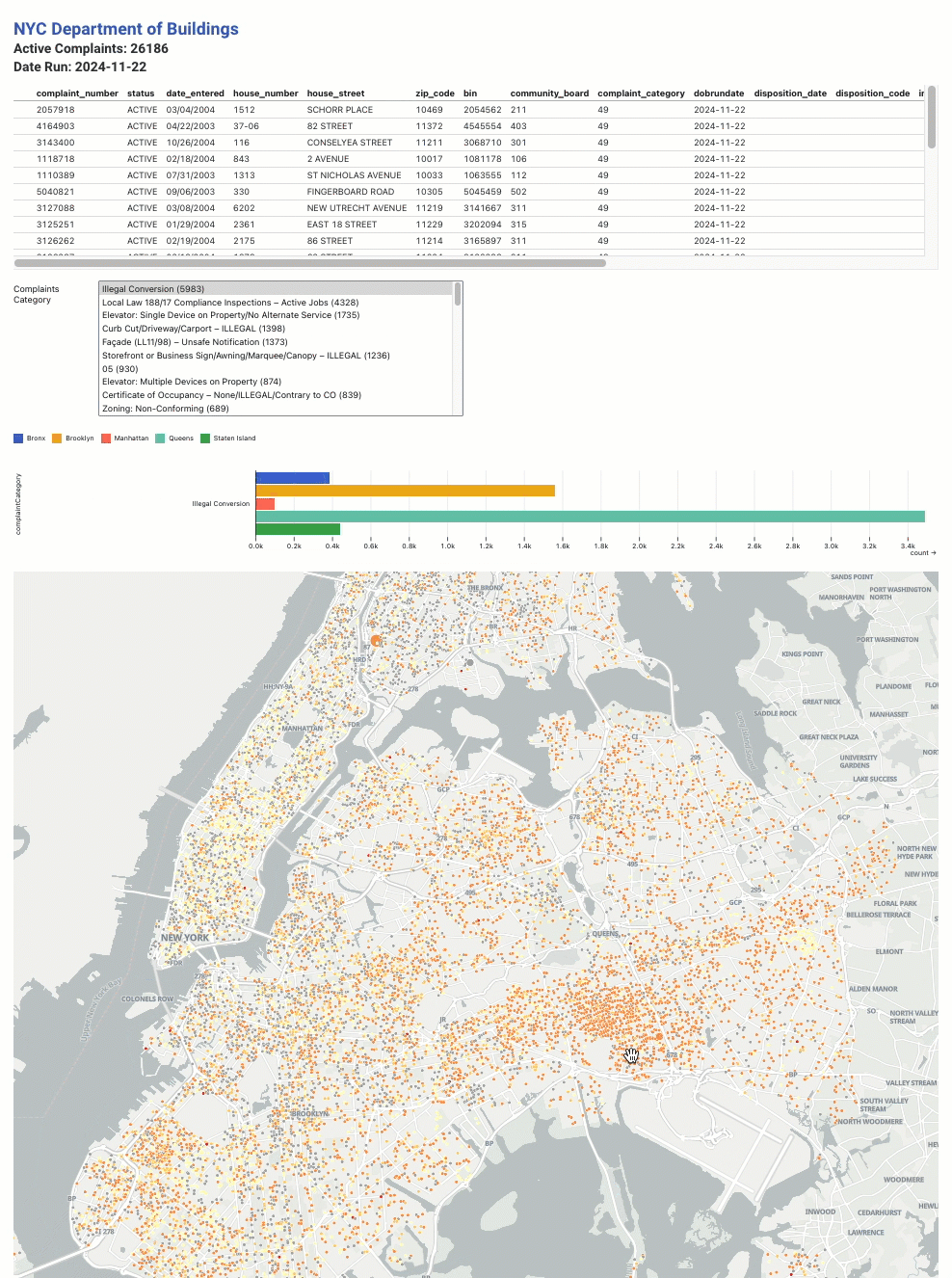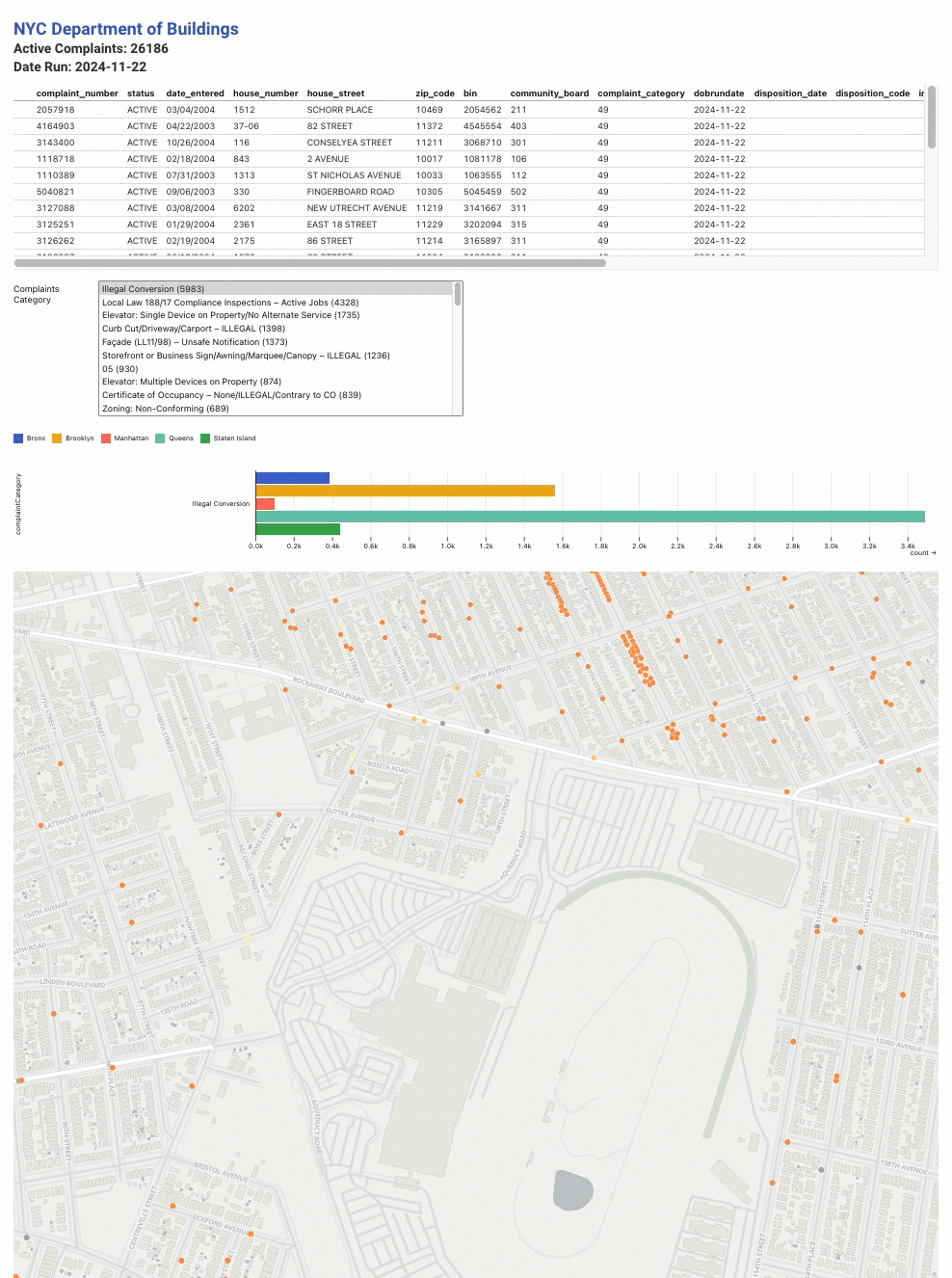
NYC Department of Buildings Active 311 Complaints
Previous work
After some publicized incidents in NYC with building maintenance lasy year, I threw together an interactive map of all of the complaints lodged to the 311 department with the NYC Department of Buildings. To my surprise, there were over 600k complaints that were active (out of over 3 million records), with many of them lacking any inspection date or resolution. The volume of complaints gave me pause, so I didn't end up writing it up or publicizing it much (the app was thrown together in a weekend, and the code looked it). I also wasn't happy with the fact that it was a snapshot of data that is updated on a pretty regular basis (unlike the National Bridge Inventory), so I put the application on the backburner until I had more time to figure out a simple ETL with mapping pipeline that I could run off a CRON job locally on a daily or weekly basis.
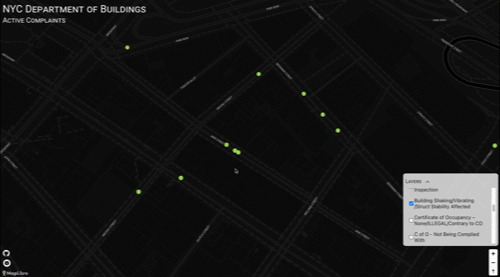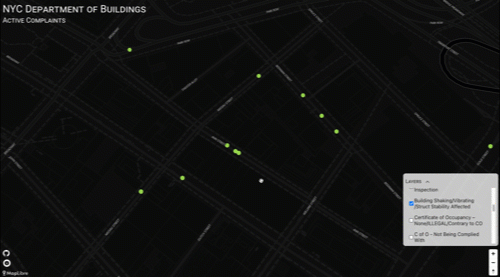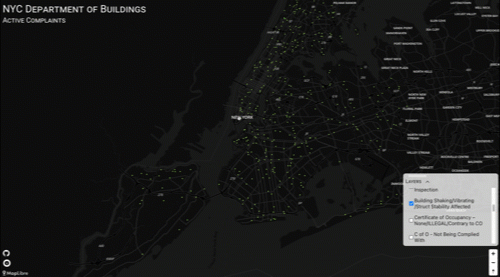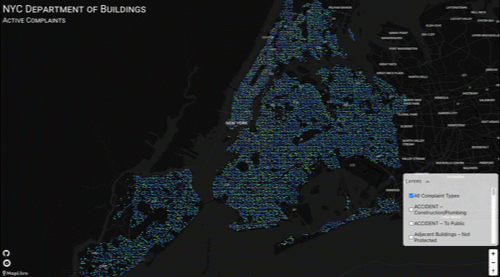
Bad Data
As it turns out, the data was bad (I pulled the information in April 2023). When I picked this project up a week ago, the first thing I did was the full CSV download from NYC Open Data, and I noticed that the number of complaints in the db had decreased by a count of nearly 500k records! And that 600k "ACTIVE" complaint volume was now less than 30k. Without some inspection heroics, there was no way that it indicated a massive increase in inspections in 2023-2024, so I used Visidata to do some quick and dirty comparisons between the two data sets.
Visidata has this neat feature where you can effectively do a df.merge on two different files with a few keystrokes:
vd /Users/mclare/DOB_Complaints_Received.csv /Users/mclare/DOB_Complaints_Received_20241121.csv
I made the complaint number the key column on two sheets, one of which was filtered to the ACTIVE data only (to get those 600k entries)
s s & inner
which created a join sheet based on the inner join between the two data sets.

Discrepancies I found:
- There were a number of duplicate keys/complaints (rows that had zero difference across all fields).
- The original dump had a variety of values in the
dob_run_datefield, which should have been the current date (as in the date I pulled the data, not some time in 2018).
I don't know when/where the discrepancies were dealt with, but since I started pulling data last week, I'm getting a consistent dob_run_date for all records.
Python Data Loaders with the US Census Geocoder
The first time I did this, I mixed in a lot of different scripts while I was initially exploring the data. I'd used Node and D3 for some things, and then Python/Visidata/Pandas for others. I decided to unify everything into a single data loader that ran a Python script to do the following:
- Query the NYC Open Data API for only active complaints (this was very easy to set up an API key, which I tested with Postman)
- Load the result of the API call into a dataframe, and create a new column for the concatenated address string required for a geocoder.
- Dedupe the address strings, and check against the existing geocode address file that I had from my previous exploration. This was done to avoid making unnecessary calls to the US Census Geocoder
- The US Census Geocoder allows a maximum batch request of 10000 entries. I took the address strings that didn't turn up a match in the existing geocode file and split them into equal chunks to make asynchronous requests to the geocoder, and then stitched the results of the async calls together.
- Merged the complaint data frame with the unique address one as a
innerjoin, to get a dataframe with only matched lat/longs from the geocoder. - Used the merged df to generate a
FeatureCollectionthat I could feed intotippcanoeto generate Protomaps vector maptiles (pmtiles, rather thanmbtiles)
One of the requirements for using data loaders with Observable Framework is that you need to feed something to stdout, because the mechanism for running the data loader in the first place depends on whether the file generated by the data loader already exists in the cache. So technically I had to write a shell script as a data loader that ran the python script and then ran tippecanoe, with the complaints.csv as the required artifact generated by the data loader and the pmtiles file from tippecanoe command as a side effect.
If I was expecting a giant file of complaints, I'd probably revise this process further, but I was only getting about 3.5mb for complaints.csv, which is fine for loading into the browser at runtime for some of the other non-map elements in the dashboard.
#!/usr/bin/env sh
DATE=$(date +%Y-%m-%d)
cd ~/workspaces/nyc-dob-observable/src/data || exit
~/.virtualenvs/nyc-dob/bin/python3 complaints.py
tippecanoe -z20 -o "nyc-buildings.pmtiles" -r1 '--cluster-distance=1' --cluster-densest-as-needed --no-tile-size-limit --extend-zooms-if-still-dropping "${DATE}_nycdob_rollup.json" -l "nyc-buildings" --force
rm "${DATE}_nycdob_rollup.json"
So now I had a csv of complaints, and a pmtiles vector tileset for all the complaints I was able to geocode with the US Census Geocoder. FWIW, I was able to get a ~98% address match with the free geocoder, which is good enough for me on a side project.
Observable Framework Components
I've already built one map with Observable Framework, but this time around I wanted to try to make more reusable components. I was only partially successful due to hitting some edges with Observable Framework.
Things I couldn't do with Observable Framework:
- import
jsonfiles intoReactcomponents (I had some classification data dumps for the categories that are JSON files) - use existing styling from the old map with Material UI. This appears to have been a pain point for others as well!
- import styled components from Ant Design
- import
cssfiles intoReactcomponents (so I couldn't use CSS modules either :( )
I ended up resorting to styling within the React components themselves (but not inline at least).
const styles = {
keyStyle: {
display: "inline",
fontWeight: 700,
textTransform: "uppercase",
fontSize: "0.875rem",
letterSpacing: "0.02857em",
fontFamily: '"Roboto","Helvetica","Arial",sans-serif',
},
valueStyle: {
display: "inline",
fontSize: "0.875rem",
fontFamily: '"Roboto","Helvetica","Arial",sans-serif',
},
entryContainer: {
marginBottom: "0.5rem",
},
};
Things I could do with Observable Framework:
- create
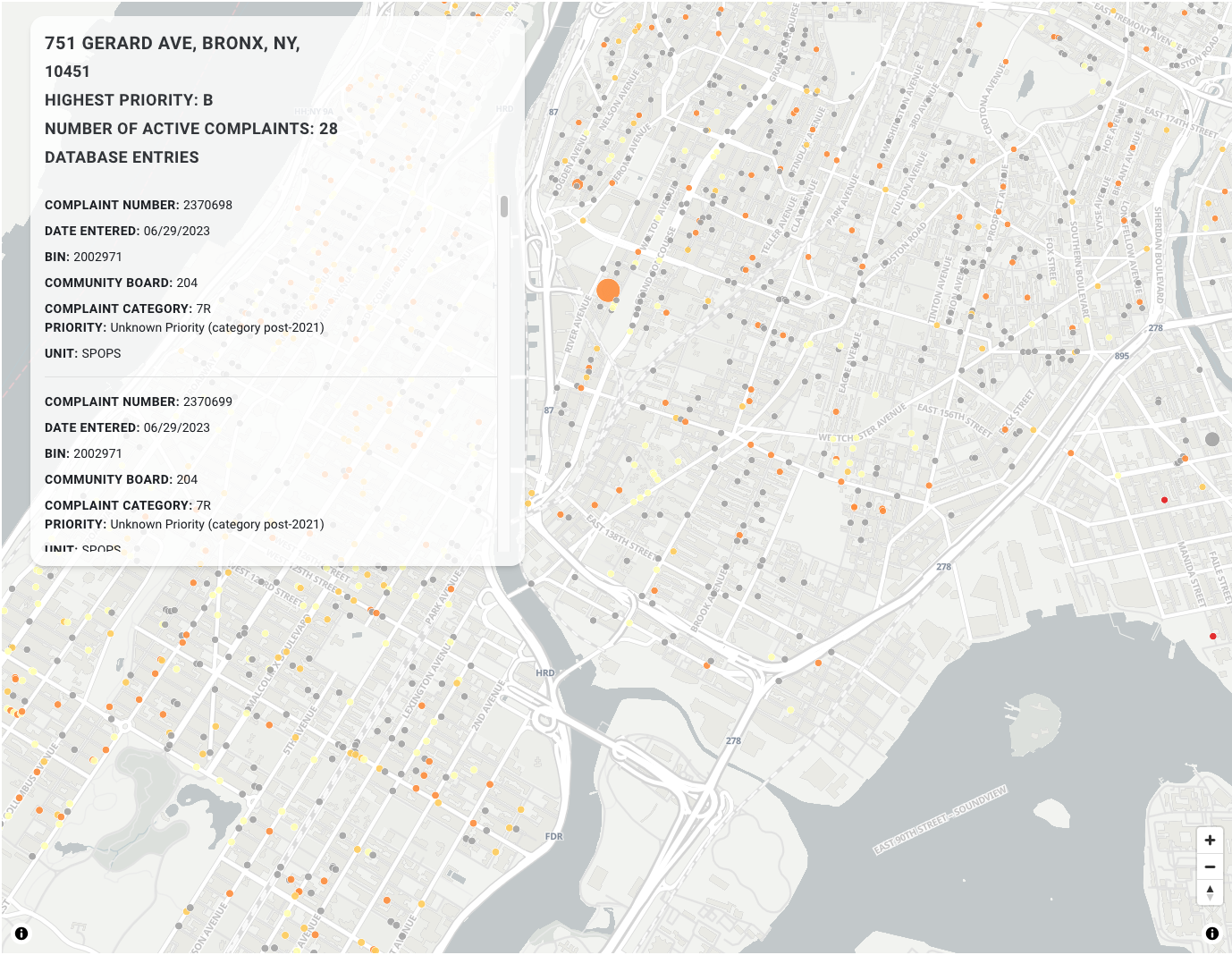
Reactcomponents with state! I used this to be able to keep the HUD from my original map. - quickly additional plots with Observable Plot based on the original
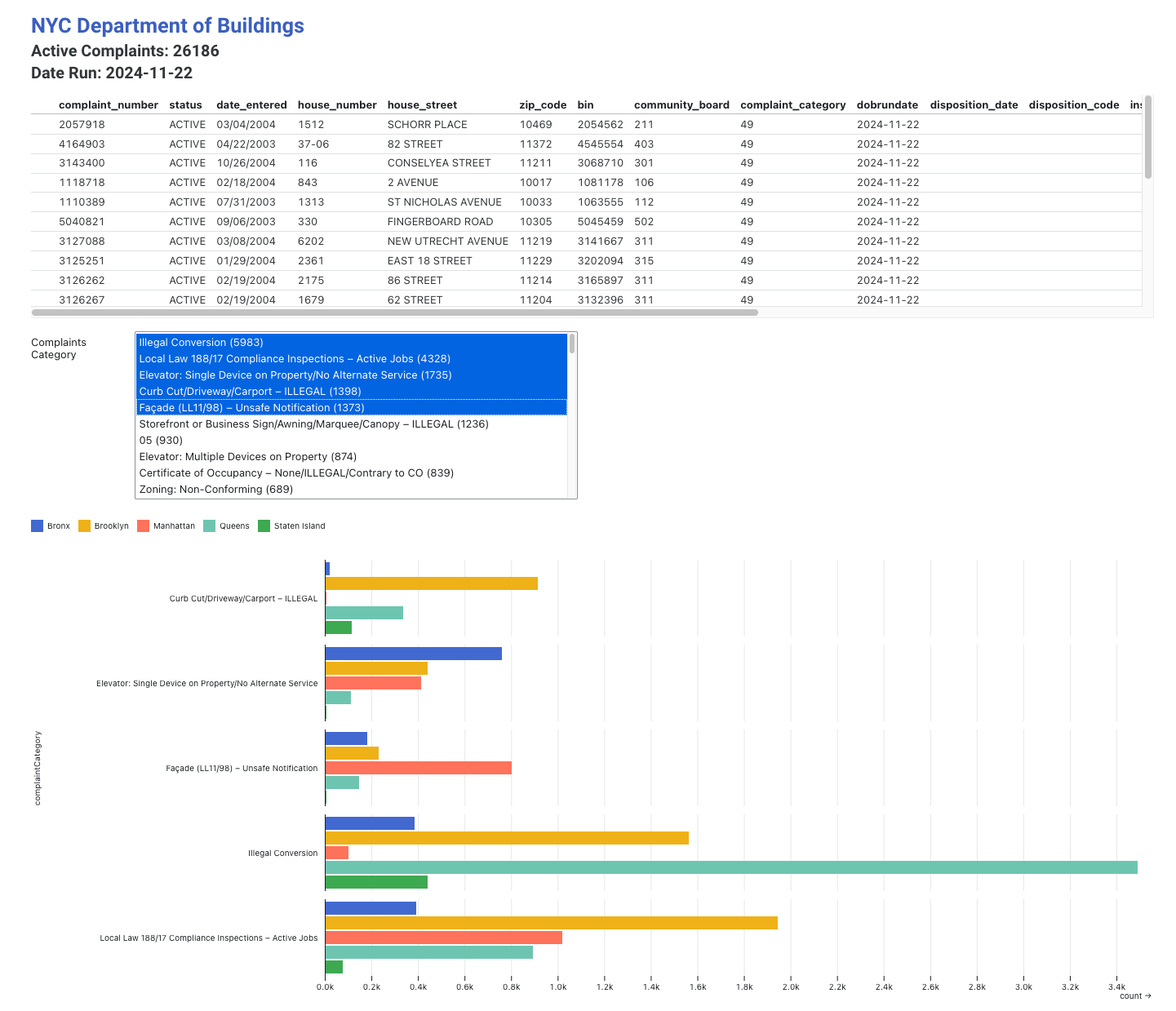
complaints.csvfile. I added a table view of the raw data, as well as a multi-select component for viewing complaints grouped by complaint type and borough.
Is anyone surprised that the most prevalent complaint is for Illegal Conversion of a building?
My index.md file still feels a bit too verbose, but there was only so much I could make into components at this point, particularly with the recurring import errors. I still can't reference files (like the tilesets) from a component, so all that loading logic has to exist in the Markdown file. I also haven't figured out (except for adding to the CRON script itself) how to dump the cache for every run. If I don't dump the cache, the data loader won't re-run, so I won't get an up to date map or data set. I was hoping to handle this by using environment variables to check if a file for the date of the CRON job exists already, but this doesn't seem to work currently outside data loaders or page loaders in Observable Framework, so I can't have an env variable inside the markdown file (or React components).
Github Repo: nyc-dob-complaint-map-observable
Final site: NYC Department of Buildings Active 311 Complaints