Why Structural Engineers Use Excel

Anyone who follows me on Twitter (or knows me IRL) knows that I have a deep-seated dislike of Microsoft Excel. My first task in my engineering career involved copying and pasting exported data in specific shapes to new spreadsheets, so I taught myself enough VBA to avoid doing that for weeks. I also had an Excel-free stint in academia where I worked exclusively in Python. When I came back to consulting engineering, I was immediately immersed in eldritch spreadsheets twice removed from the original designer for a very complicated project with a bunch of terrifying VBA macros. Not surprisingly, this did nothing to improve my perception of Excel as a design "tool".
I've had notes on this subject for months, thanks to Colin Caprani's talk on Excel is Evil - Why it has no place in research, but have finally had time to put together what the issues are specifically for design, and what the alternatives (paid and free) are.
So why do we use Excel?
-
It's cheap. -- I've never worked for company that didn't use Microsoft Office in some capacity. Some of them didn't use Outlook to handle email (cries in LotusNotes), but Word was the standard for word processing; Powerpoint was the standard for presentations; and Excel was the standard for design calculations. You'd never buy these separately, so it's just an easy freebie that you already have.
-
It's ubiquitous. -- Even the most junior engineer (and oldest engineer) has used Excel. Their prowess with it will vary widely though, and I've seen some terrible different-equation-in-each-cell spreadsheets from both the old and young.
-
It can quickly summarize information. -- The job of an engineer is defined by demand-capacity ratios; Excel makes it easy to drag down formulas and see where rows exceed a certain value.
-
It's reactive. -- This is probably the biggest reason that Excel is so popular. It's trivially easy to make a change on one cell and see the impact propogate immediately on dependent cells. This is known as a "reactive programming interface", and it's something engineers take for granted.
Why shouldn't we use Excel?
-
It has no version control. -- Everyone has seen (and made) a spreadsheet with $DATE_$SUBJECT_$OWNER_$VERSIONNUMBER... that inenvitably exceeds the max 31 characters and obscures exactly what changes were made between v22good and v22a. In software, this is dealt with through something called version control (with the dominant paradigm being git). I have seen Excel plugins that do some form of version control, but a single drag of a column could result in thousands of formula changes that confuse what the real change was (especially if it's a change in the base data (from an analysis model with some tweaks, for example). In reality, you could "git" an Excel spreadsheet, as it's just an xml schema at heart, but you'd still have a massive "diff" (the command used to track difference between changes on a file).
-
It's inflexible. -- A lot of the tricks that I tried to use to improve my Excel experience only went so far. The first company I worked at had very detailed calculation book standards (your calcbook should be self-explanatory and create an engineering narrative), which did not lend themselves well to having sidebar notes in cells that would print properly for hardcopy documentation or peer review. Variables are assigned per workbook, rather than per worksheet, so defining a column or beam detailed design per worksheet quickly breaks down if you're trying to be descriptive in your formulas. Engineering calculations also often need diagrams or other images, and putting those into Excel is equally a formatting disaster.
-
It's opaque. -- It is hard to tell what cell equations using column-row addresses do on a glance (colored cell outlining does help...if it's in the same worksheet), and it's even harder to read nested conditional statements combined with INDEX-MATCH. There is no easy way to format equations in a cell for readability. The best I was able to do was to induce multiple lines of an equation, but if someone clicks the cell, they'll only see the first line in the formula bar unless they've increased that field size.
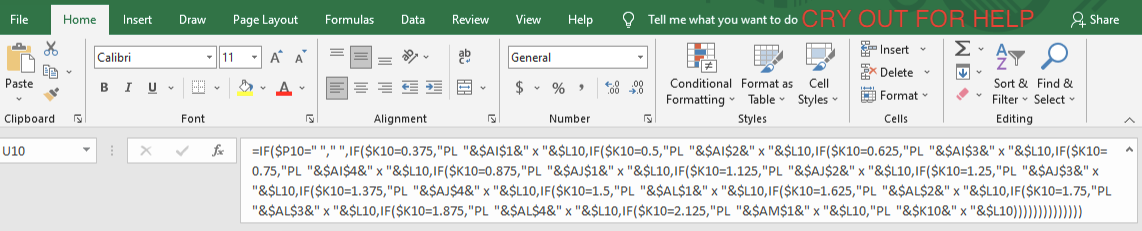
- It has side effects. -- Probably the most glaring one I struggled with on a daily basis involved print formatting. Evidently, it is too hard to ask that a page be formatted and printed the same way between being opened in different sessions. While VBA can help with certain things, there's also no built in way to undo a VBA command (yes, you can download a button or create your own script, but this is a pretty effing terrible oversight). There are also certain really stupid visual bugs in Excel (particularly in the Mac version) that have never been fixed.
What are the other paid options?
There are, and have been for quite some time, multiple other paid options for the types of calculations typically performed in Excel. The two I've encountered are Mathcad (since 1986) and Tedds (now owned by Tekla). I used Mathcad at an internship nine years ago, but it wasn't particularly popular due to the lack of batch calculations (one of the things Excel does nicely). TEDDs seems to be popular because it has standard templates and calcbooks for common calculations, but I believe it's more UK/EU code specific (again, haven't used it ever in the U.S.). Another proprietary paid platform I've seen recently is Blockpad, which appears to try and address some of the weaknesses I've noted above for Excel.
What are the free open source options?
While the things I've noted above have been covered by other dissidents from Excel, I haven't seen a piece that addresses how the strengths and issues above can be addressed using open source programming (with Python libraries). I've noted with an asterisk (*), which pieces I've used myself, but some of these features are still relatively new. While no one really wants to deal with dependency hell and getting Python configured just right, I still think this is the way to get better 'hand' calculations, and these add-ons are part of a growing and developing ecosystem used by many other fields.
The basic building blocks that I recommend utilizing are Jupyter notebooks/Jupyterlab with a number of add-ons.
-
Jupyter notebooks* are basically the standard operating practice for data science these days. They allow you to create a narrative in markdown or text cells, alongside calculation/code cells, which can come from a number of different programming languages. Each notebook has its own active Python kernel, and variables can be used across multiple cells. One of the downsides of Jupyter is that in its base version, cells can be run out of order (i.e. not from top to bottom), which could affect variable values. As long as you understand how cells work, this shouldn't be an issue though.
-
Transparent step-by-step calculations* -- handcalcs -- This is a great free library (that even includes unit conversion!) which will allow you to write and typeset formulas nicely in LaTeX without using LaTeX. You will also be able to substitute in values for clarity.
-
Batch calculation* -- Papermill -- This allows you to substitute specific values and generate notebooks/reports on an element by element basis.
-
Version control* -- nbdime or jupyterlab-git -- As noted above, this is a critical shortcoming of Excel, and was initially an issue with Jupyter as well, but there are now several options to verify changes in notebooks.
-
Custom templating -- Jinja -- You can use custom templates to replicate the "hand calc" type notepads and set global formatting for page numbers and page breaks.
-
Remote hosting/template control* -- Binder or Jupyterhub -- This helps get around having to install custom Python configurations (basically all the pieces listed above) on every single work machine, which can be a headache to maintain (and may be against IT policies as well). Essentially you can self-host a "hub" from which notebooks can be accessed (and edited) on your local network (or online with an additional authentication layer).
-
Reactive programming -- Nodebook or Dataflow Kernel -- The development of these tools are critical to abandoning an Excel based workflow, mainly since engineers are so used to changes autopopulating dependent cells. I don't think it's necessarily a bad thing that Notebook cells are not run until you explicitly execute them, but for Excel diehards, this is low-hanging fruit for criticism of the Jupyter ecosystem.
Other pieces that you might find useful:
- Dash/Plotly - interactive plots and visualizations using Python wrappers around Javascript's React and D3.
- Pandas - data analysis and tabular manipulation - gotta make those DCR tables!